
Processing Petabytes of Data Daily: Precise Lineage Tracking with an Offline Data Governance Platform Based on DolphinScheduler

This article introduces an offline data governance platform built on DolphinScheduler, addressing issues like task dependency black holes and scalability bottlenecks. By implementing YAML-based dynamic compilation and automatic lineage capture, the platform enables efficient task dependency management and data tracking. It leverages the Neo4j graph database for lineage storage, supporting second-level impact analysis and root cause localization. Additionally, with a self-developed high-performance data import tool, data transmission efficiency is significantly improved.
Background and Challenges
Under the pressure of processing petabytes of data daily, the original scheduling system faced two major issues:
Task dependency black holes: Cross-system task dependencies (Hive/TiDB/StarRocks) were manually maintained, resulting in troubleshooting times exceeding 30 minutes.
Scalability bottlenecks: A single-point scheduler couldn't handle thousands of concurrent tasks. The lack of a retry mechanism led to data latency rates surpassing 5%.
Technology Stack
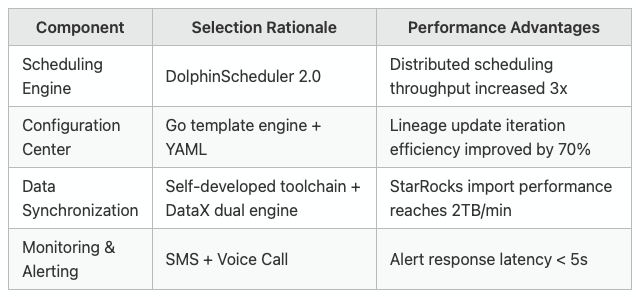
Core Architecture Design
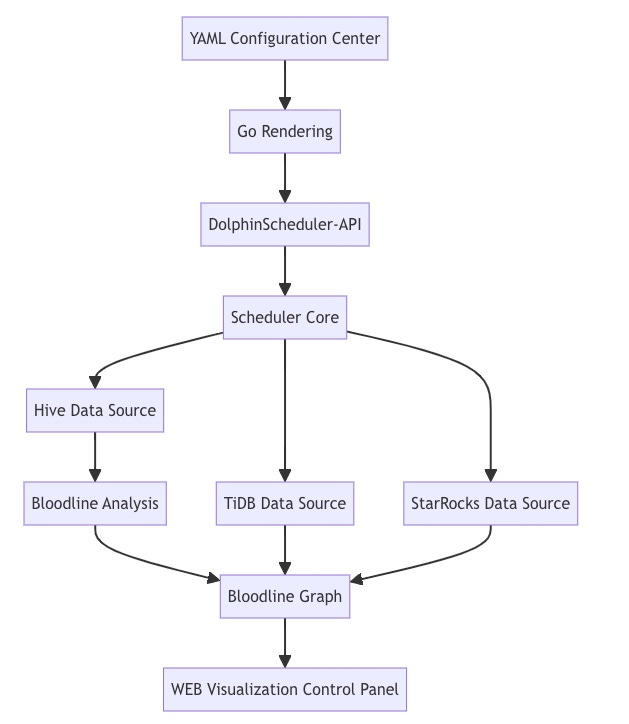
Key Technical Implementations:
YAML Dynamic Compilation
type TaskDAG struct {
Nodes []Node `yaml:"nodes"`
Edges []Edge `yaml:"edges"`
}
func GenerateWorkflow(yamlPath string) (*ds.WorkflowDefine, error) {
data := os.ReadFile(yamlPath)
var dag TaskDAG
yaml.Unmarshal(data, &dag)
// Convert to DolphinScheduler DAG structure
return buildDSDAG(dag)
}
Automatic Lineage Capture
Intercepts SQL execution plans to parse input/output tables
For non-SQL tasks, uses hooks to capture file paths
# StarRocks Broker Load Lineage Capture
def capture_brokerload(job_id):
job = get_job_log(job_id)
return {
"input": job.params["hdfs_path"],
"output": job.db_table
}
Solutions to Key Challenges
Zero-Incident Migration Plan
Dual-run comparison: Run both old and new systems in parallel; use the DataDiff tool to verify result consistency
Canary release: Split traffic by business unit in stages
Rollback mechanism: Full rollback capability within 5 minutes
Self-Developed High-Performance Import Tool
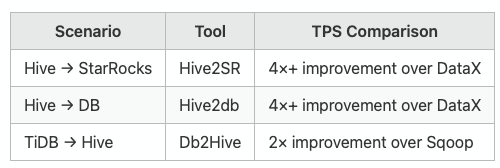
Key Optimizations:
Batch submission using Go's coroutine pool
Dynamic buffer adjustment strategy
func (w *StarrocksWriter) batchCommit() {
for {
select {
case batch := <-w.batchChan:
w.doBrokerLoad(batch)
// Dynamically adjust batch size
w.adjustBatchSize(len(batch))
}
}
}
Lineage Management Implementation
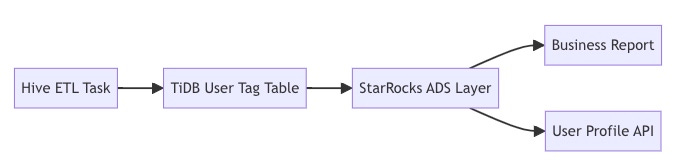
Lineage data is stored in the Neo4j graph database, enabling:
Impact Analysis: Locate the affected scope of a table-level change within seconds
Root Cause Analysis: Trace the source of an issue within 30 seconds during failures
Compliance Auditing: Meets GDPR data traceability requirements
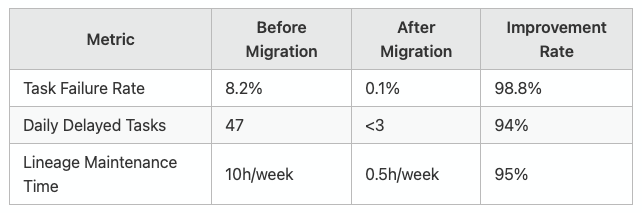
Performance Gains
Join the Community
There are many ways to participate and contribute to the DolphinScheduler community, including:
Documents, translation, Q&A, tests, codes, articles, keynote speeches, etc.
We assume the first PR (document, code) to contribute to be simple and should be used to familiarize yourself with the submission process and community collaboration style.
So the community has compiled the following list of issues suitable for novices: https://github.com/apache/dolphinscheduler/contribute
List of non-newbie issues:
https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22help+wanted%22+
How to contribute:
GitHub Code Repository: https://github.com/apache/dolphinscheduler
Official Website:https://dolphinscheduler.apache.org/en-us
Mail List:dev@dolphinscheduler@apache.org
X.com:@DolphinSchedule
YouTube:https://www.youtube.com/@apachedolphinscheduler
Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
Contributor Guide:https://dolphinscheduler.apache.org/en-us/community
Your Star for the project is essential, don’t hesitate to lighten a Star for Apache DolphinScheduler ❤️
Thank 🙏 your posts very useful and making adaptation easy and less scary. For the future post could you consider and describe data build tool in term of Dolphin 🐬 there also some other open source which didn’t support it, maybe there is a reason for it or/and some cases where alternative solution exist in dolphin 🐬